Introduction
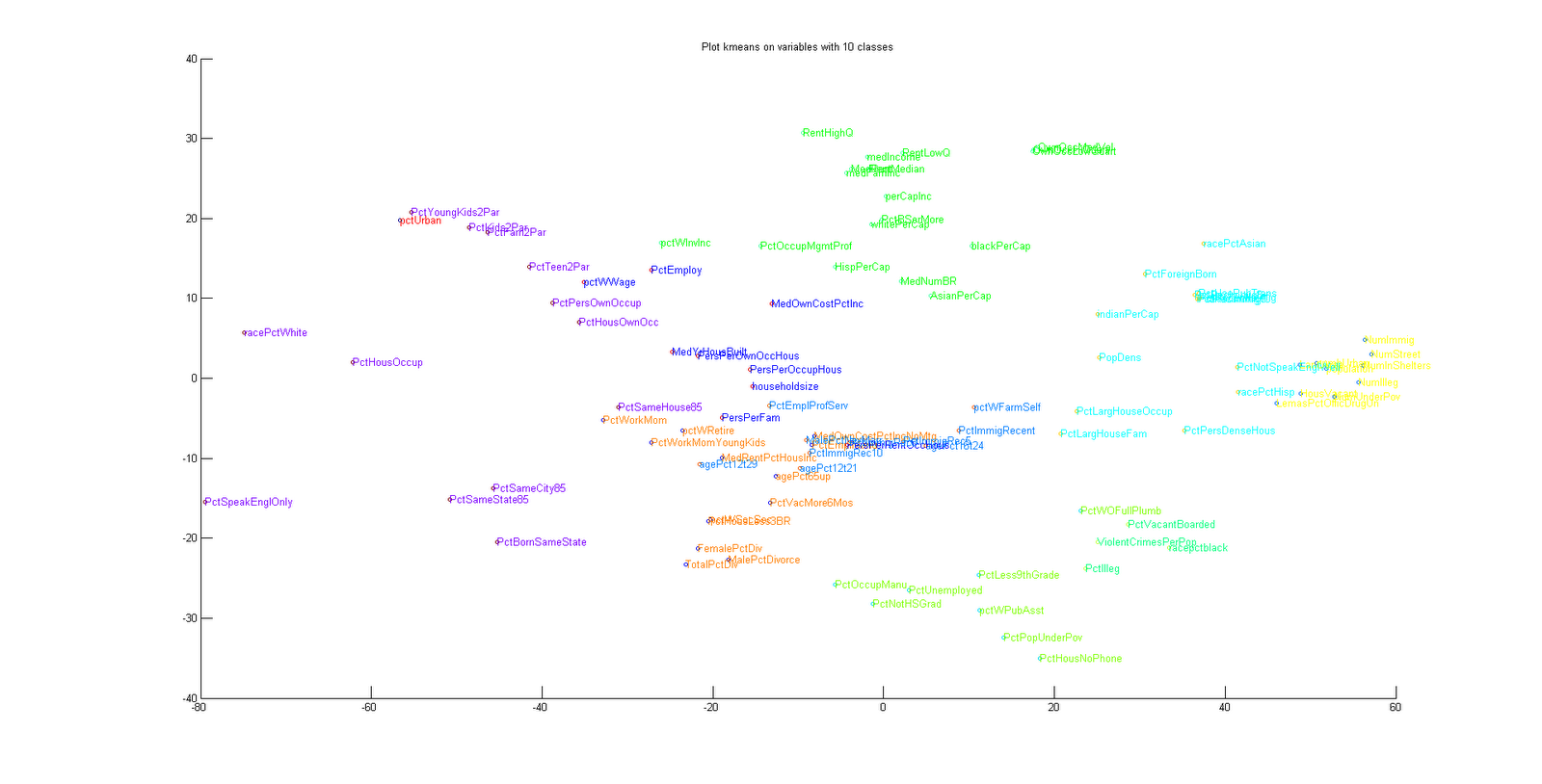
The must appropriate selection on variables is the cluster of five elements.This grouping offers the particularity to give the same number of cluster than the agglomerative classification method.
The first group
PctForeignBorn,PctHousNoPhone,PctIlleg,PctLargHouseFam,PctLargHouseOccup,PctLess9thGrade,PctNotSpeakEnglWell,PctPersDenseHous,PctPopUnderPov,PctRecentImmig,PctRecImmig10,PctRecImmig5,PctRecImmig8,PctVacantBoarded,PctWOFullPlumb,pctWPubAsst,PopDens,racepctblack,racePctHisp,ViolentCrimesPerPopThe first group is composed by immigrant or illegitime children, living in large house not really graduate , not speaking english, under poverty, with public assistance, on a dense area. This group is near our targeted value.
Black and hispanic
The second group
HousVacant,indianPerCap,LandArea,LemasPctOfficDrugUn,numbUrban,NumIlleg,NumImmig,NumInShelters,NumStreet,NumUnderPov,PctUsePubTrans,population,racePctAsianThe group of workers whose use public transport under poverty with drug problems.
Asian and indian
The third group
AsianPerCap,blackPerCap,HispPerCap,medFamInc,medIncome,MedNumBR,MedRent,OwnOccHiQuart,OwnOccLowQuart,OwnOccMedVal,PctBSorMore,PctOccupMgmtProf,perCapInc,RentHighQ,RentLowQ,RentMedian,whitePerCapThe group of medium people from different race.
The fourth group
agePct12t21,agePct12t29,agePct16t24,agePct65up,FemalePctDiv,householdsize,MalePctDivorce,MalePctNevMarr,MedOwnCostPctInc,MedOwnCostPctIncNoMtg,MedRentPctHousInc,MedYrHousBuilt,PctEmplManu,PctEmplProfServ,PctHousLess3BR,PctImmigRec10,PctImmigRec5,PctImmigRec8,PctImmigRecent,PctNotHSGrad,PctOccupManu,PctUnemployed,PctVacMore6Mos,pctWFarmSelf,PctWorkMom,PctWorkMomYoungKids,pctWRetire,pctWSocSec,PersPerFam,PersPerOccupHous,PersPerOwnOccHous,PersPerRentOccHous,TotalPctDivThe group of worker manual, immigrant , unemployed, with a big family , in a dense house and area.
The fifth group
PctBornSameState,PctEmploy,PctFam2Par,PctHousOccup,PctHousOwnOcc,PctKids2Par,PctPersOwnOccup,PctSameCity85,PctSameHouse85,PctSameState85,PctSpeakEnglOnly,PctTeen2Par,pctUrban,pctWInvInc,pctWWage,PctYoungKids2Par,racePctWhiteThe perfect group , white and living on the same area, speaking in english with two kids, urban.
The white race disturb the idea of this group.







































{kind=link}